Abstract summary:
Diagnostic troubleshooting is a complex, step by step and iterative process in which the technician observes symptoms, collects basic diagnostics information, performs a series of tests to narrow down the root cause. The proliferation of in-vehicle applications and increasing complexity of advanced electronics / E/ E Architecture across various functional areas have made it almost impossible for a technician to memorize the whole vehicle system information to identify the root cause. This evoked the need for intelligent systems that can do complex deduction and induction reasoning and arrive at the solution. We propose that the state-of-the-art large language models are well suited to solve these challenges effectively. In this white paper, we give an overview of our approach towards solving real world vehicle diagnostics issues using large language models.
Introduction:
Complexities in Diagnostics troubleshooting
Modern vehicles have 100+ Electronic control units, wiring harness connections that touch tens of thousands, of software lines of code. Normal vehicle operation is the culmination of the interaction between complex set of components, subsystems both hardware and software. It is becoming difficult for technicians to understand the complex vehicle behavior and trace the root cause from the generic problem symptoms. For OEMs (Original Equipment Manufacturers), the inability to diagnose the issue will lead to an additional cost for cost of training workforce and increases warranty losses. Automotive OEMs are in constant need to improve diagnostic accuracy at scale throughout their value chain. In this white paper, we give you a brief introduction to large language models and our solution approach to solve diagnostics problems.
Introduction to Large Language models (LLM)
Large language models are advanced artificial intelligence (AI) systems designed to analyze, process and generate human language. These models are typically based on deep learning algorithms and are trained on massive amounts of textual data, allowing them to generate coherent and contextually relevant responses to natural language queries.
Large language models can understand and process human language at a very sophisticated level, allowing them to perform a wide range of language-based tasks such as translation, summarization, question-answering, and even creative writing. They are widely used in various fields, including natural language processing, machine learning, and artificial intelligence.
Some of the most popular large language models include OpenAI’s GPT (Generative Pre-trained Transformer) models, Google’s BERT (Bidirectional Encoder Representations from Transformers) model, and Facebook’s RoBERTa (Robustly Optimized BERT Pre-training Approach) model. These models have achieved remarkable success in various language-based tasks and have opened new possibilities in natural language processing and artificial intelligence research.
A model specifically trained with detailed vehicle system information would be able to understand the cause/effect, parent/child relationships. It would then be able to do deductive, inductive or abductive reasoning based on its natural language understanding like a human. The end user such as technician can give it a set of premises and then ask the model to draw conclusion.
Diagnostic assistant system design
The high-level system design for an AI assistant based on LLM (large language model) that can run on a Windows application is as follows:
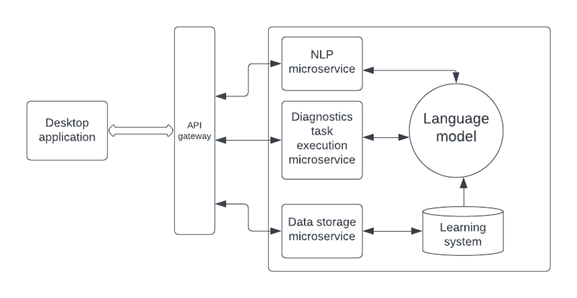
Figure 1: AI assistant based on large language model
Development approach
In this section, we provide an overview of model training and deployment process.
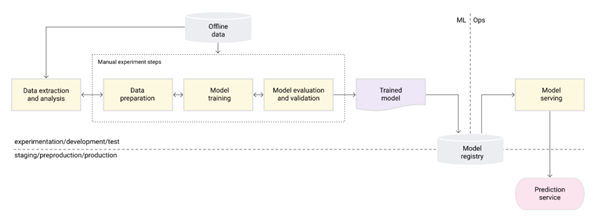
Figure 2: Development approach
• Collection of relevant data
Automotive system engineers have all the relevant data about components, sub-system and system level functionality in system description document. Textual data then needs to be analyzed for factual accuracy, causal chaining from problem symptoms to root cause. Few examples of the document include Component specification, functional requirements document, functional test cases, system requirement documents, software documentation etc. LLM models can be trained on this data to create mathematical representation of vehicle system behavior in terms of normal, adverse scenarios etc.
• Training the model
The training process typically involves a pre-training phase where the model is trained on large, unstructured datasets, followed by a fine-tuning phase where the model is fine-tuned on a smaller, domain-specific dataset. The pre-training phase usually requires significant computational resources, and the fine-tuning phase involves careful tuning of hyperparameters and training algorithms to optimize the model’s performance. Reinforcement learning with human feedback is performed for better alignment with the end user expectations.
• Deploying the model
The trained model can be deployed in cloud server and can be accessible via API calls. This enables the model to be utilized in different applications such as desktop, mobiles etc. By providing a chat interface, we enable the technician to interact with the model by providing the symptoms observed and then ask for suggestions. The technician can also provide feedback on whether the suggestion provided by the model is good or not. This can then be used as a dataset to retrain the model.
• MLOps (Machine Learning Operations)
MLOps (Machine Learning Operations) is a set of practices that enable the development, deployment, and maintenance of machine learning models at scale. In the context of large language models, MLOps is particularly relevant because these models can be computationally expensive to train and require careful monitoring to ensure their accuracy and safety. MLOps practices for large language models include automated testing, continuous integration and deployment, and version control, and monitoring for bias, security, and ethical considerations. By using MLOps, developers can create more efficient and effective workflows for developing and deploying large language models, leading to better performance, scalability, and reliability.
Conclusion
In conclusion, the use of LLM in problem solving can revolutionize the automotive diagnostics domain. By analyzing system documents and identifying patterns and trends, LLM can help automotive technicians make more informed decisions and provide better diagnostics results to their clients. The ability to instantly search and analyze large volumes of technical data can also help reduce the time and cost associated with training the workforce. As technology continues to advance, we can expect to see more applications of LLM in various areas of engineering design feedback, field support, technician training etc. The use of LLM has the potential to increase the efficiency and accuracy of diagnostics delivery, benefiting vehicle customers and the OEM ecosystem.